
Groq
AI inference at unprecedented speed
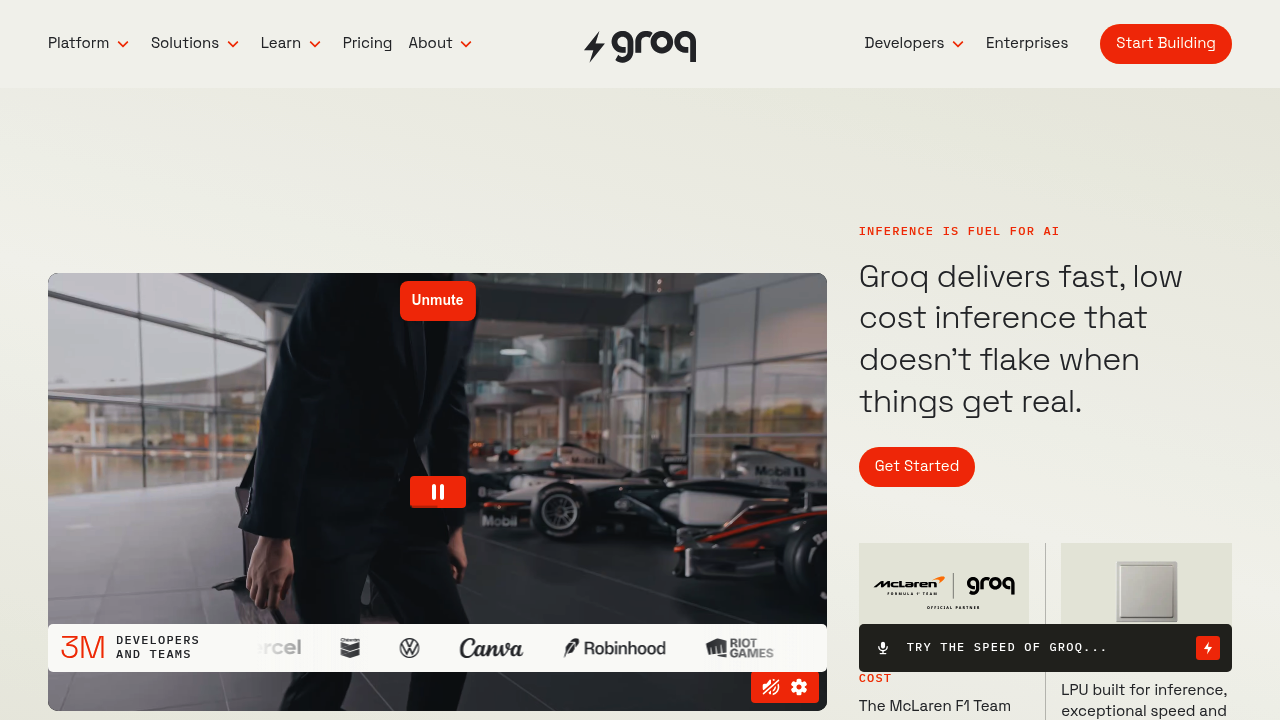
Speed matters when you're running inference at scale. Groq delivers exactly that with its specialized LPU Architecture — processes AI models faster than traditional GPU setups. The difference becomes obvious when you're handling thousands of requests per hour.
Reviews (0)
Log in to write a review
No reviews yet. Be the first to review Groq!
🔗 Similar AI Tools
Discover more tools in this category
1
 2
2
 3
3
 4
4
 5
5
 6
6

Claude
Jan 5
Teams wanting AI that doesn't compromise on privacy find Claude refreshing
ChatGPT
Jan 5
ChatGPT answers almost anything
Gemini
Jan 5
Google's latest AI assistant handles code debugging
DeepSeek
Jan 11
DeepSeek doesn't reveal specific API pricing details upfront
Grok
Jan 11
Grok's output quality hits different than most AI assistants
Dify
Jan 11
Agentic workflows separate Dify from other no-code builders
No reviews yet
Write Review
×
![Screenshot]()