
CerebrasCoder
CerebrasCoder runs GLM 4
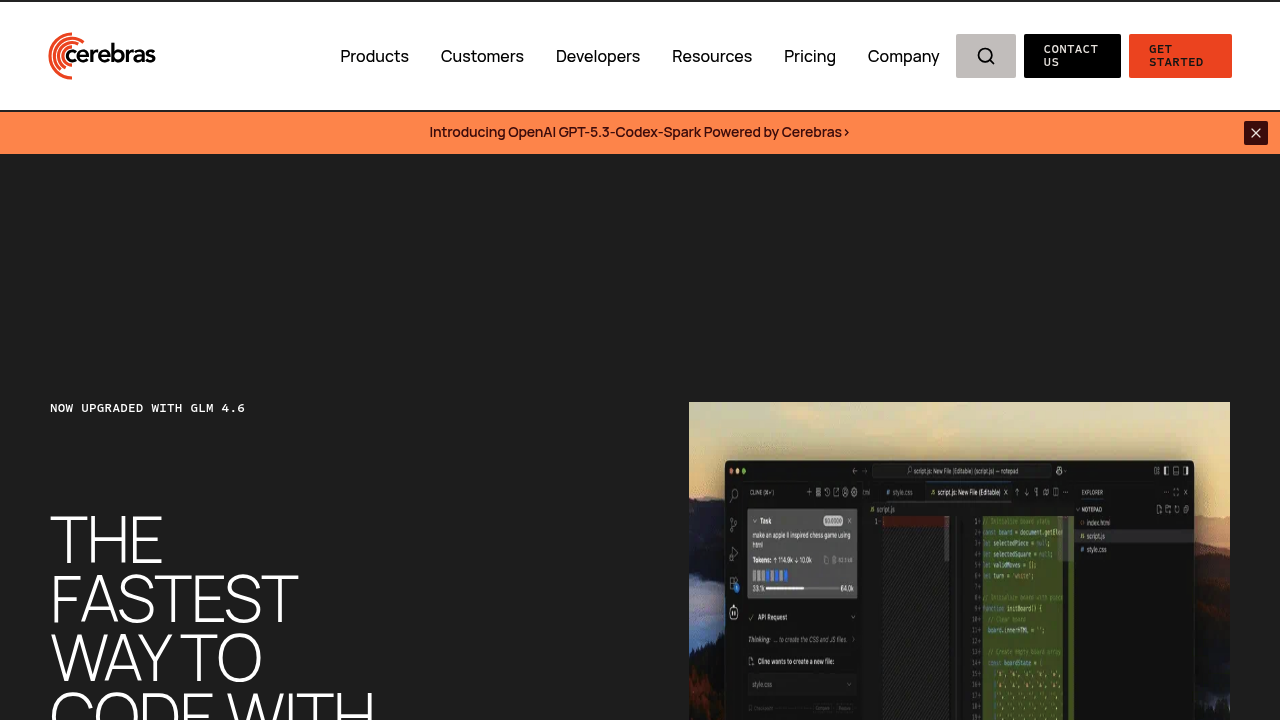
CerebrasCoder runs GLM 4.6, an open coding model, at speeds exceeding 1,000 tokens per second. This service is built on Cerebras inference infrastructure, which pushes throughput high enough that code generation feels nearly instantaneous during active development sessions. GLM 4.6 ranks first on the Berkeley Function Calling Leaderboard for function calling accuracy, which matters when the model needs to invoke functions, parse APIs, or interact with external systems during code generation.
At a Glance
Pricing Plans
- GLM 4.6 access with limited tokens and requests
- Great for trying out Cerebras inference
- Building small demos
- GLM 4.6 access with fast, high-context completions
- Up to 24 million tokens per day
- 3-4 hours of uninterrupted vibe coding
- Ideal for indie devs, simple agentic workflows, weekend projects
- Coming Soon
- GLM 4.6 access for heavy coding workflows
- Up to 120 million tokens per day
- Ideal for full-time development, IDE integrations, code refactoring, multi-agent systems
Reviews (0)
Log in to write a review
No reviews yet. Be the first to review CerebrasCoder!
🔗 Similar AI Tools
Discover more tools in this category

Claude
Teams wanting AI that doesn't compromise on privacy find Claude refreshing

ChatGPT
ChatGPT answers almost anything
Gemini
Google's latest AI assistant handles code debugging

DeepSeek
DeepSeek doesn't reveal specific API pricing details upfront
Grok
Grok's output quality hits different than most AI assistants

Dify
Agentic workflows separate Dify from other no-code builders