Traditional AI tools hand you one model's answer. Sup AI works differently.
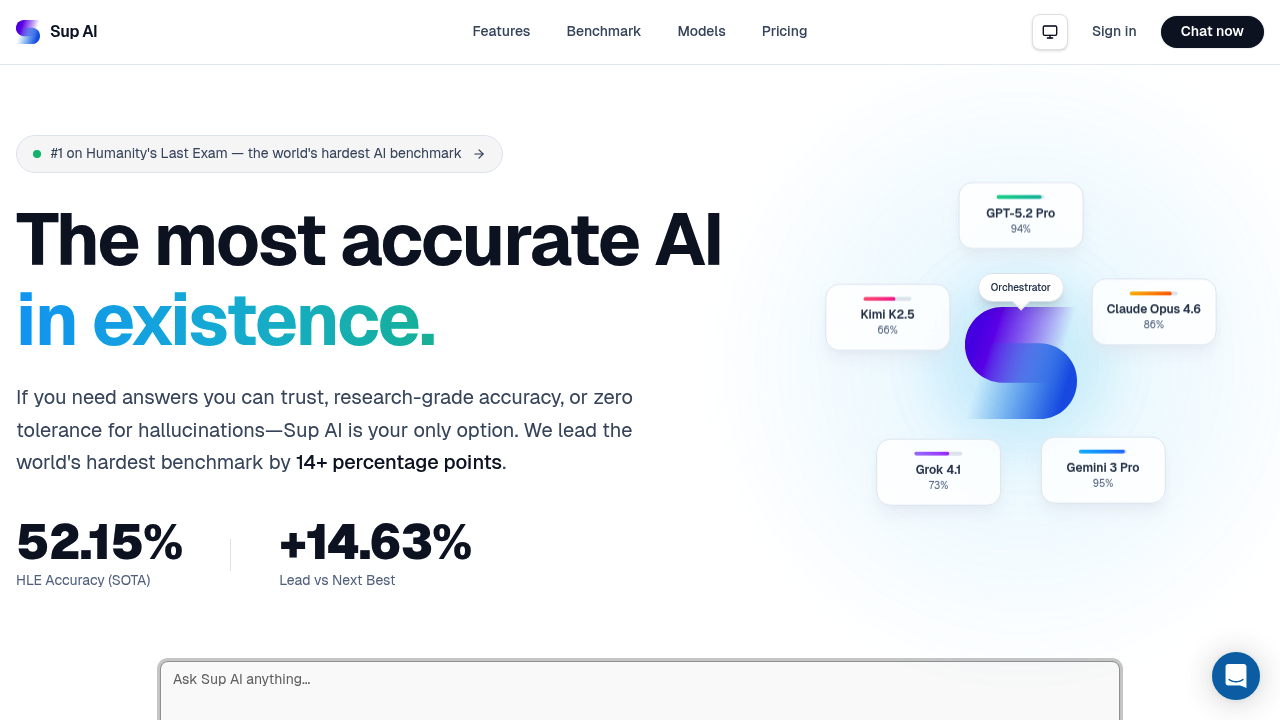
Your question gets routed to whichever frontier model handles it best. Then it combines their strengths through multi-model orchestration. The orchestrator taps up to 27 models. Confidence drops below a threshold? It automatically retries your query. You get logprob confidence scoring in real-time—so you're not guessing whether the answer's solid or shaky.
Every claim includes inline citations. No hedging. No vague references. Just verifiable sources baked into each response. Sup AI maintains what it calls perfect memory through multimodal RAG. Everything becomes permanent knowledge. You can create and edit images with natural language commands—and those images sit in context like regular text.
Sup AI posted 52.15% accuracy on Humanity's Last Exam. That's a benchmark with 3,000 questions across 100+ subjects (created by over 1,000 domain experts). It beat Gemini 3 Pro Preview by nearly 15 percentage points—Gemini hit 37.52%. GPT-5 Pro reached 31.64%. Claude Opus 4.5 Thinking managed 25.2%. The evaluation used enhanced settings—web search and low-confidence retries included. Sup AI ran it themselves in December 2025. Not officially endorsed by the benchmark's creators.
A research analyst digging through contradictory studies might actually benefit here. The calibration error sits at 36.54%. That's not trivial. There's a free plan. Can't tolerate hallucinations? Need research-grade accuracy? This leans hard into verifiability over speed.